大家好,我是不会写代码的纯序员 Chunel。今天,我想跟大家聊聊,我在Caiss中,对ANN算法做了哪些优化。

| 介绍 |
ANN(Approximate Nearest Neighbor)算法指的是用于解决海量高维向量中,相似度检索问题算法的集合,是一套算法簇的集合。主要分为:基于树的算法(如kdtree、annoy等),基于索引的算法(如ivf等)和基于图的算法(如HNSW、NSG等)。所需要解决的问题,无非是两个:
- 如何更快的在集合中查询到topK个相似向量
- 如何确保快速召回的topK个向量,尽可能的准确
近几年,大量实验已经证明,基于图的算法在这两个方面都有较大的优势。具体的性能比较,大家可以到年薪百万的知乎上搜索一下,这方面的对比还是比较多的。不过,那些曲线图看看就好,因为你很难通过那些对比数据,看出自己需要找的具体数据集合(比如:1000w个300维向量)的性能,而且不同算法的不同的参数设置,对最终的性能和效果的影响也是很大的。
我的意见是,如果数据量不是特别特别大的话(上亿级别,压垮服务器内存),就直接上Caiss
[Caiss源码链接]吧。Caiss底层是基于HNSW (Hierarchical Navigable Small World 平行可导航小世界)算法,性能和精度极大的优化的同时,方便上手,更是能帮你完全免掉参数设置的麻烦。
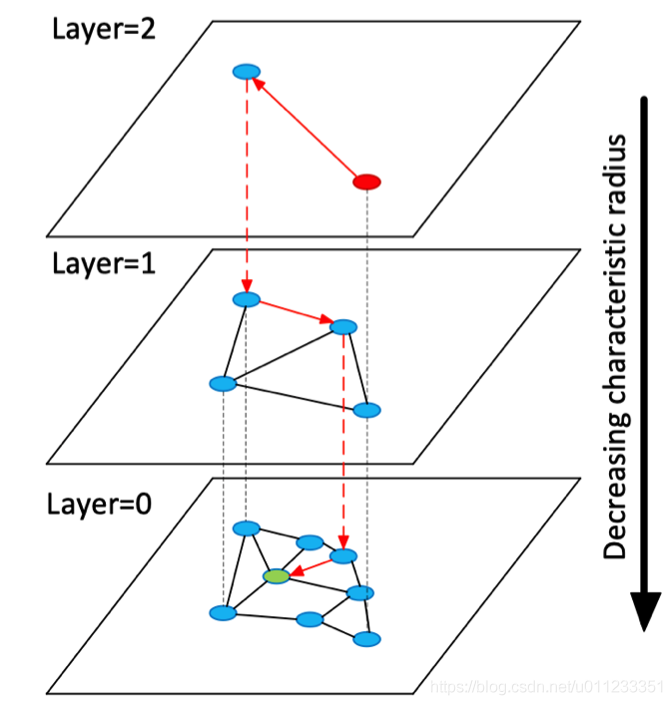
在这里,先简单罗列一些HNSW算法的信息,供大家参考:
下面进入正题,主要介绍一下本人在Caiss中做的模型和计算方面的优化。
| 模型优化 |
Question1:HNSW(包括所有的ANN算法)的功能是通过给定向量,搜索距离相近的向量,属于vec2vec的搜索。但在日常的开发任务,经常是需要label2label。举个例子,我们做图像搜索的时候,如果我们通过vec2vec的方式查询,需要第一步将传入的图片embedding成向量(vec),再通过这个vec在给定的向量池中快速找到距离最近的topK个vec,然后将这topK个vec映射回图片的标签,从而找到相似图片。这个流程对开发来说相对繁琐,而且还需要专门加入类似数据库的内容,用来记录label和vec对应的信息。
Solution1:为了解决来回映射的问题,Caiss在算法模型中引入了双向哈希结构,支持传入label直接在模型中映射成vec,也支持搜索到的近邻vec映射回对应的label。结果就是使用Caiss,在开发过程中只需要传入图像的label,就可以直接得到相似图片的label,极大的简化的工程链路。
Question2:在做ANN任务的时候,更头疼往往是算法和参数选取的问题。这么多种算法,每种算法又这么多参数。选什么算法,设什么参数,对搜索结果有什么影响,这样的问题想想就令人抓狂。特别是针对一些不太了解这些算法的开发人员来说,这简直就是灾难。
Solution2:为了更好的让大家入门并解决实际问题,Caiss中加入了自动训练的功能。不同于深度学习的神经网络算法,图搜索算法基本上都有一个特点,就是节点的出度(即一个点连接的周边点)越大,准确度越高,与之对应的是,搜索效率越低。基于这一点,Caiss在训练的过程中,屏蔽了算法参数选取的过程,直接根据用户设定的精确度(precision)信息进行多轮(epoch)迭代训练。并且在每次训练的时候,根据当前模型精确度与目标值的差距(span)自动调优参数,直到达到目标为止。
Question3:“增删查改”是搜索任务中最常见的需求。HNSW是基于平行图的搜索算法,在构图的时候点点相连。插入流程和构图流程基本相同,但是如果删除其中的某个节点,会引起整个图结构改动,最糟糕的情况甚至可能需要重新构图。
Solution3:为了解决删除的问题,Caiss在HNSW模型的模型中,加入了Trie(字典树)结构,将需要删除(忽略)的节点的label,放入Trie中。每次搜索的时候,相比topK值,多召回一些节点。如果召回的节点的label在Trie中,则在返回结果中过滤。
这样做主要有两个好处:一个是在删除的label数量巨大的时候,既节省了空间,又能够快速查询;第二个就是这种解决方法不会引发引擎算法模型的重建,而且还方便恢复之前删除的信息。
| 计算加速 |
计算海量向量相似度的过程,涉及到了超大量的浮点计算,非常吃计算性能。为了加速计算,Caiss引入了eigen计算和指令集计算,通过尽可能的减少中间计算过程,在工程层面极大的加速了查询速度。
此外,Caiss中还提供了机器学习中的降维(SVD)算法,在保证准确度基本不变的情况下,通过减少单个向量维度的方法,来降低计算量,从而加速查询过程。
还有,相似度计算的任务中,特别是在语义认知任务中,很大一部分都是基于cos距离来判断相似度。Caiss在计算cos距离的时候,将cos距离计算转换成inner(内积)距离计算,并且将单个vec和其多个邻近点vec的inner距离计算流程并行化。相比于直接计算cos中的开根号的方式,精确度无影响的同时,又极大的减少了计算量。
| 结束语 |
以上这些优化,保证了Caiss在模型和计算性能上,有了极大的优化。当然了这些还远不够,下一章纯序员会主要跟大家聊聊,Caiss在工程层面做了哪些优化,比如开辟缓存、实现并发、SQL和批量查询的引入等。大家继续期待哦。
还有就是,如果大家在使用Caiss的过程中遇到了什么问题,或者是有什么意见,请联系我。我会尽可能在周末有空的时候,跟大家一起去解决这些问题,并且努力把它做的更好。
[2020.11.08 by Chunel]
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
github地址: https://github.com/ChunelFeng