大家好,我是不会写代码的纯序员——Chunel Feng。前段时间,在日常搬(hua)砖(shui)之余,我花了一些时间对CGraph中的底层线程池(C++版本)进行了优化。引入了一些优秀的机制,并进行了相关性能测试。
在这里跟大家分享一下,其中的一些技巧和成果:主要包含了thread-local机制、任务盗取机制、负载均衡机制、lock-free机制、自动扩缩容机制、批量任务处理机制等。当然,以下这些内容也仅局限在我自己的认知范围,如果大家有什么好的意见和建议,欢迎大家随时提出。如果能帮忙测出几个bug,那就更好了,哈哈哈哈。

首先,还是照例,先上源码链接:CGraph源码链接
其中,线程池的实现在/src/UtilsCtrl/ThreadPool/文件夹中
| 背景介绍 |
图框架中,会涉及到有些彼此不依赖任务,需要并发执行。这个时候,如果是在执行任务的过程中,通过反复开闭线程来实现,就有点太说不过去了。我们需要通过一个高性能的线程池来对线程进行统一管控和循环使用。
相比Java、Go等高级语言,原生的CPP在多线程方面落后的可不是一星半点。就拿Java来说吧,在语言层面就提供了好几种线程池的封装和实现,各种同步/互斥机制也很完善。完善到什么程度捏,嗯,就这样说吧,连我都能用,嘿嘿。
但提到CPP,就比较呵呵了。在CPP11版本之前,别说是线程调度了,就连最简单的开辟线程功能,都只能依赖第三方库实现——顺便说一句,boost库作为std库的“提前体验”版本,其中也包含threadpool的功能,也不知道有多少人知道,多少人用过。
CPP11版本之后,官方也开始学(co)习(py)Java,提供了一些语言标准库层面的支持,比如std::thread,std::mutex,std::unique_lock,std::promise,std::atomic等,进而还有后面更新一些的版本支持的std::shared_mutex,std::shared_time_mutex 等功能。不过,直到今天也还是缺失了很多功能,比如官方threadpool,又比如同步屏障(barrier)等。
在开始开发之前,本着学(zhan)习(tie)借(fu)鉴(zhi)的优秀态度,我也在github和B乎上看了一些CPP线程池的实现。有的版本star是挺多的哈,但给人感觉基本上还是比较simple的,单纯是为了实现功能而实现,并没有太多性能方面的考量和优化。

于是我决定自己从头开始实现一个版本。至少咱要比github上搜到的要好吧,否则咱都不好意思说自己逛过pron*hub。反正我认识这么多老师,不懂的就问就是了。
| 提出问题 |
通常,在讲(tree)优(new)势(bee)之前,都要先踩一下其他的竞品的不足。上学参加竞赛的时候如是,追女神的时候如是,竞赛没拿到名次、女神也没追到的现在依旧如是。
线程池嘛,主要功能就是管理调度线程,节省线程重复申请/释放所带来的损耗。我们先来聊一聊现在github和B乎上找到的一些通用实现方法。很多的思路都很简单:一般就是提供一个接口,可以把任务塞入一个queue中,交由线程池中的线程异步执行,然后等待(也可以不等待)结果返回。
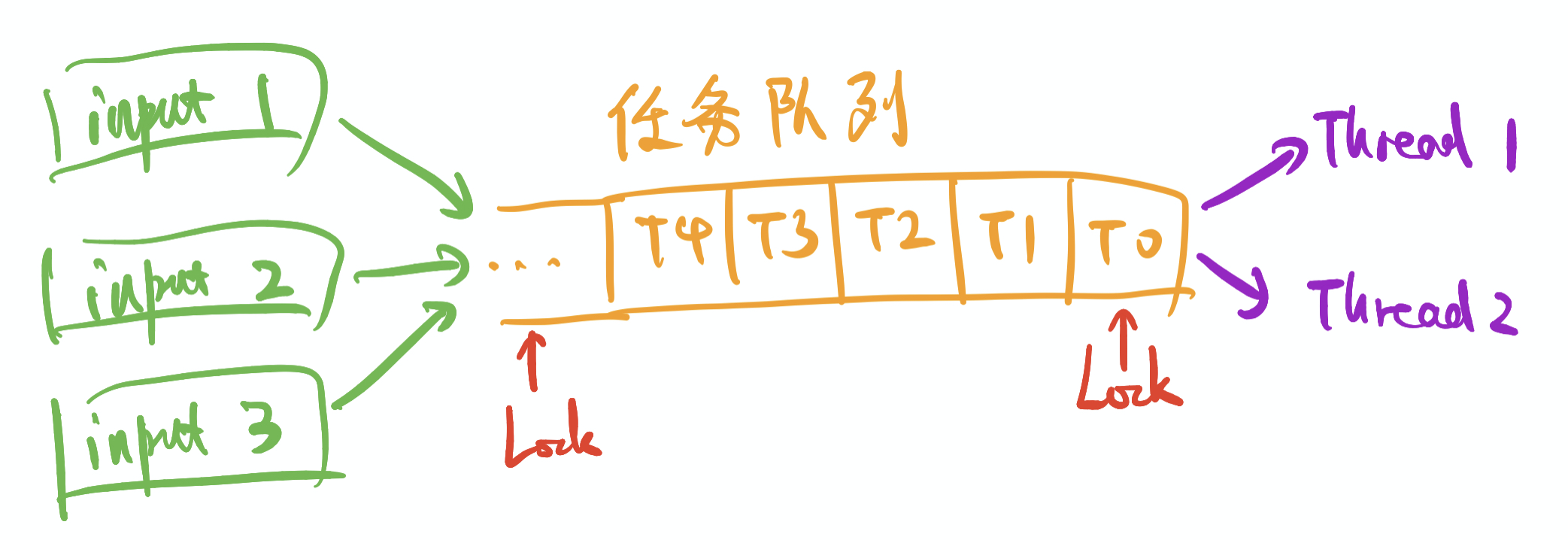
看上面的图,m个(图中为3个)输入源把待执行的任务,放到一个任务队列中,然后线程池中的n个(图中为2个)线程,依次去消费这个queue。这是最基础的版本,最简单的模型,同时也是问题最多的。
你看哈,我们用两个线程处理queue中的任务,如果这一刻任务数量忽然暴增,我们还只用两个线程处理么?或者说,长时间队列都是空的,我们还保留两个线程么?
你再看哈,在input的时候,队列尾部是需要加锁的,不然多个输入源,不就乱套了么。再讲究一点要判断是否超出规定大小啥的。当有任务输入的时候,需要发送一个信号,去通知pool中的线程:来接客了。哦,不对,是来处理任务了。
这个时候,没有在处理任务的thread就会过来去从queue的头部,获取一个任务然后执行了。注意,这个过程也是需要加锁的,对应图中T0下面的那个红色的Lock。当然了,这其中还会涉及到如果queue为空时候的等待处理。
我们设想一种情况,此刻pool中一共有5个thread可以运行,而queue中有3个任务,分别是Task0,Task1,Task2吧。会发生什么,这5个thread去争抢Task0的执行权,其中有一个拿到了,满意的去执行了。然后接下来4个thread再去争抢Task1任务的执行权,一个成功之后,剩下的3个thread再去争抢Task2的执行权,over。
我再这里说【争抢】,其实就是抢锁的一个过程,因为从queue中获取任务是需要上锁的,这个过程是有等待损耗的。而且,理论上这种one by one的同步,相对是很耗时的。
基本上所有提升并发的优化,都是有两个最基本出发点:一个是增加扇入扇出,一个是增加负载。这话不是我说的哈,是一位不愿意透露所在公司的阿里云高P大佬说的。翻译过来,就是批量进出,批量执行。可能高阶一些的还会提到命中缓存啥的,那基本上不是纯并行处理的范围(或者说,那也是批量执行的一部分)。
| 设定目标 |
做一个东西之前,总要给自己设定一点目标。否则做着做着可能就跑偏了,最后写出来个内存池也说不定。

我们先把flag定下来:
- 开箱即用,基于std库纯手工实现,兼容mac/linux/windows跨平台使用,无任何第三方依赖。
- 简单易用,无脑往threadpool中塞任务即可,支持任意格式(入参、返回值)的任务执行。
- 性能优异,尽可能减少调度过程中各种细节损耗(比如,new、copy构造等)。性能测试可以看出,调度性能明显优于github上搜到的排在首页的C++的线程池。
- 功能强大,各种功能参数开放设置。功能层面向Java版本看齐(这话说明暂时还没对齐,懂的都懂)。
- 稳定可靠,经历过亿次级别的测试,功能稳定正常——没想到吧,我不但会写(B)代(U)码(G),还会自测。
| 本章小结 |
这一节,主要介绍CPP生态中对线程池的支持力度的不足,讲了我在写CGraph的过程中,针对线程池优化的一些目标和思路。暂时还没说到具体的实现方式——这个将会在下一章中跟大家介绍。欢迎大家继续观望哈。
当然了,如果大家有什么好的思路和意见,也很欢迎大家提出来,或者帮忙实现一下。这样才能共同进步嘛,期待您的指教。
[2021.07.31 by Chunel]
推荐阅读
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng
