大家好,我是不会写代码的纯序员——Chunel Feng。这篇文章,是线程池优化系列连载的第二篇。不过具体会写多少篇,我目前心里也没有B数,大家就先一篇一篇的看着吧,好吧。
上一章中跟大家讲了一些CPP中线程管理调度方面的不足,和我们这次优化线程池的一些目标,偏理想。这一章主要介绍一些优化机制的具体实现,偏落地。
首先,还是照例,先上源码链接:CGraph源码链接
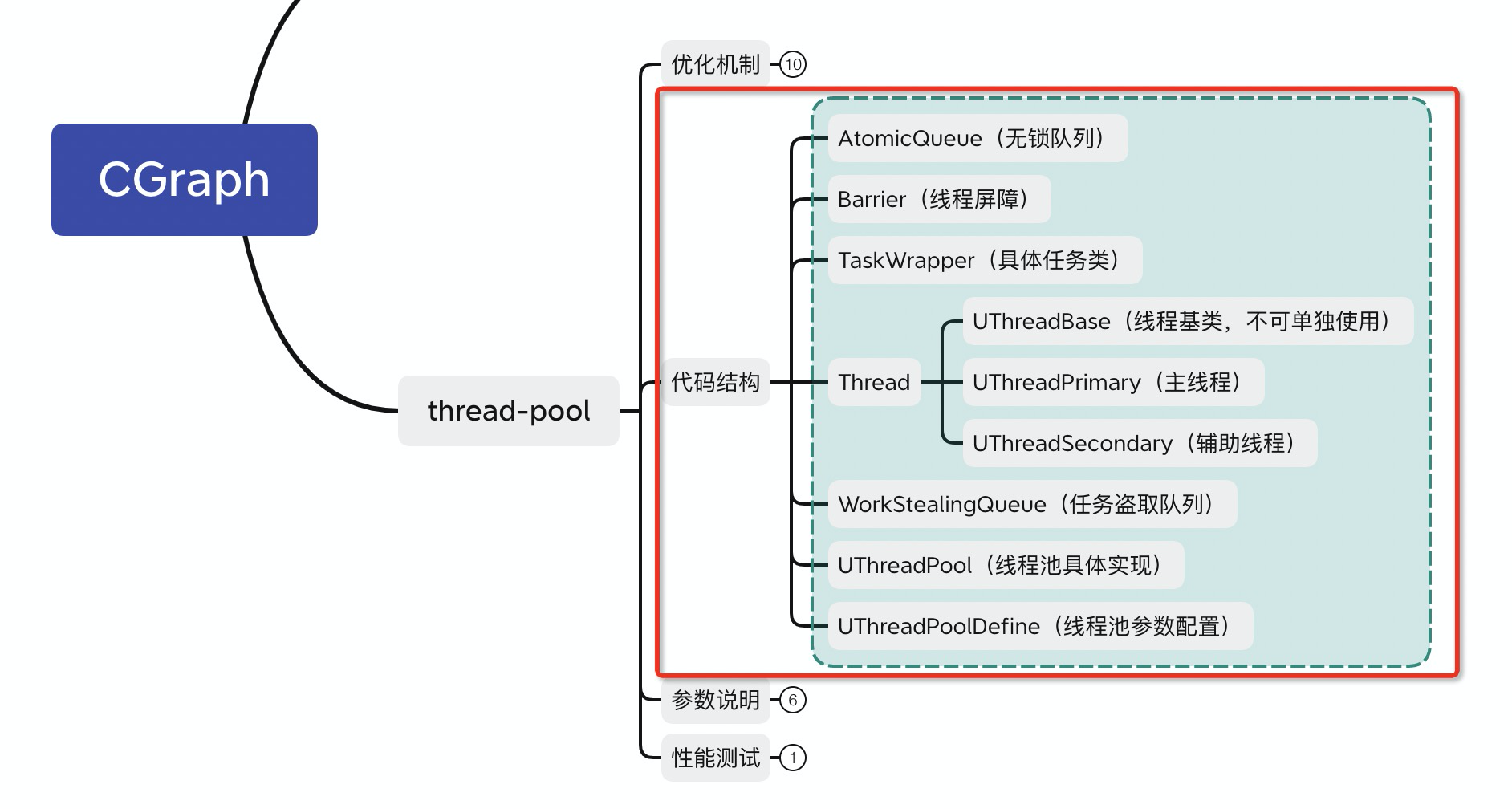
其中,线程池的实现在/src/UtilsCtrl/ThreadPool/文件夹中
| local-thread机制 |
上一章,我们分析传统的线程池的一个瓶颈,在于多个thread去【争抢】pool中任务队列中的第一个task,这里是有锁操作,会有一定的性能开销。而引入local-thread技术就是为了减少这种开销。
C++11版本开始,已经引入了thread_local关键字,但是很少有人用。具体到做工程的童鞋,其实更喜欢的方式,应该是自己封装一个属于自己的thread类,那这里的东东不就都是local了么。
为此,CGraph中封装了UThreadPrimary类,其中就包含了一个UWorkStealingQueue类的对象。这是一个类似std::deque结构的双向队列,可以从头部弹出节点,也可以从尾部弹出节点。
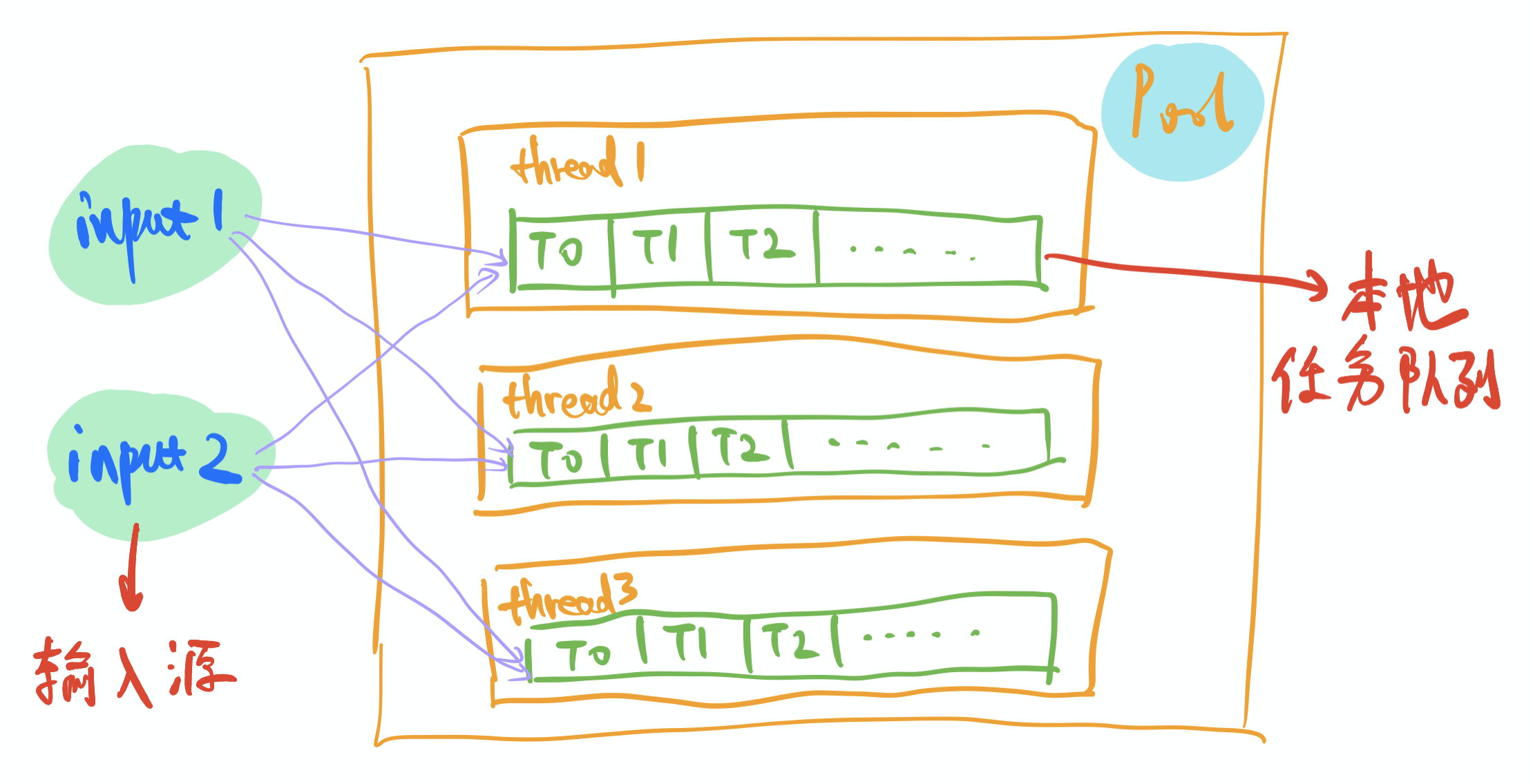
把原先pool的queue中的任务,放到不同的n个线程的私有的n个queue(UWorkStealingQueue类型)中,线程执行任务的时候就不需要再从pool中获取去【争抢】了。从而是不是就达到了“增加扇出”的效果。
再往前想一步,最初的线程池模型中,外部写入的时候也是写入pool中的queue,会存在一个【争抢】写入,也会在queue被读的时候,无法抢到锁。那写入thread中的queue的话,是不是也一定程度上提升了“增加扇入”的效果。毕竟,跟你竞争的只有本线程(local-thread)的读了鸭。
local-thread还有一点内容,就是本线程中产生的task(尽可能的)放在本线程的queue中执行。这样也是local的一种体现,而且也会在一定程度上增加线程的亲和性——这个跟线程内部资源的缓存有关。
| lock-free机制 |
lock-free是无锁编程的技术,也叫做lockless技术。lock-free也分好几种维度,比如:基于atomic的、基于内部封装mutex的、基于cas机制的,当然可能还有一些我不知道的(欢迎补充)。
无锁,乍一听像是编程的时候不用锁了,但你不加锁的同时,别人在暗中默默的帮你加了锁。举个例子,CPP中的std::atomic<int>类型,就是一种无锁类型。但其实在这种类型的变量,做多线程并发的i++的时候,在变量内部维护了一个spin-lock(自旋锁,确保当前线程不被切换)和一个cas(乐观锁,确保数值正确)。说是无锁,实际上看进去之后会发现,还不止有一个锁——只是外部程序不感知罢了。
CGraph中的UAtomicQueue类,采用的也是类似的技术(不过并不是cas,而是内部加入mutex和condition_variable来进行控制)。其实,刚才聊到的UWorkStealingQueue类,也属于无锁类型——仅是外部看上去无锁罢了。在内部封装的过程中,我们也在一些特定的情况下使用了yield()方法让出线程的执行权限,实测效果是有明显提升的。
这部分内容,后期可以考虑使用cas方式替换,试试看效果。理论上乐观锁是比悲观锁性能要好的。
| work-stealing机制 |
任务偷窃机制——这种技术常被用于线程之间相互backup的场景中,Java版本的线程池中也有这项技术。
解释一下,比如当前线程池里有3个线程,分别为thd1,thd2和thd3吧。每个线程中的local queue中都包含了100个任务——已经很负载均衡了吧。我们设想极端一些哈,比如thd3的task都是sleep 1s,而thd1和thd2中的task都是sleep 1ms。正常情况下,thd仅执行自己local queue中的内容,那这个任务总体的耗时应该是max(100ms, 100ms, 100s) = 100s。
但是在所有开始执行的100ms后,thd1和thd2就已经无工可做了(像极了35岁的纯序员本员),但是thd3还是在苦苦支撑着,一直到100s结束。这显然是不太合理的。
一种比较合理的做法是,在thd1和thd2在执行local任务结束之后,可以去thd3的队列中去stealing一些任务(就是sleep 1s的那种)执行——这就是所谓的work-stealing机制。这种机制的优势也是很明显的,针对刚才描述的情况,原先100s才能执行完的任务,整体耗时瞬间就被降低到30+s左右。
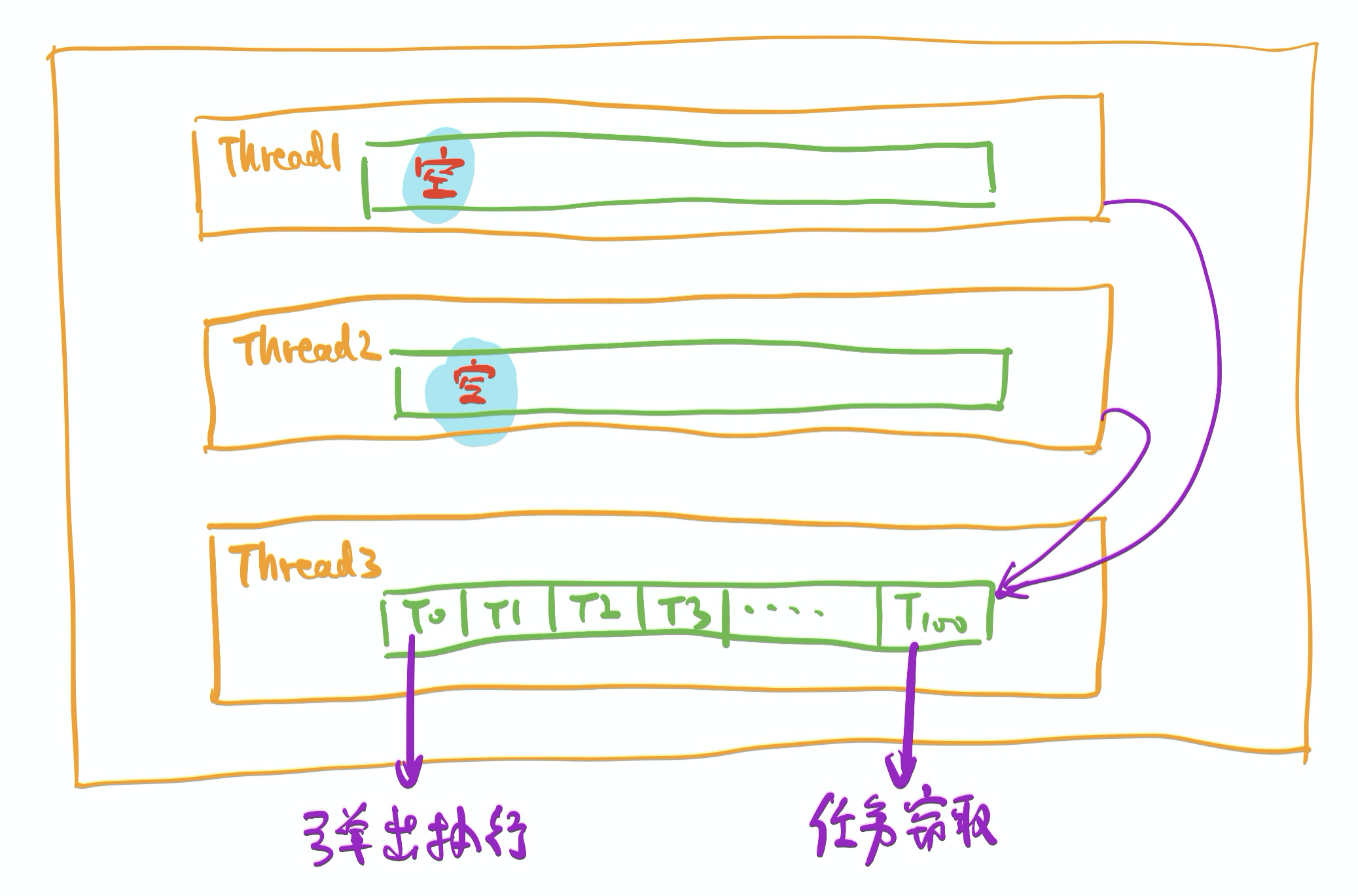
还有一个问题哈,当thread本地没有task的时候,从哪个thread去stealing呢?一般的做法,是在初始化的pool时候给每个线程设定编号:比如0~7,用index表示。thread5进行stealing的时候,一般是从thread6的queue中开始,然后thread7、thread0... 依次递推到thread4。这样做的好处,是避免了大家都从某一个thread开始stealing而导致的不均衡。每个线程在local执行任务的时候,从UWorkStealingQueue的头部弹出task,在偷/被偷的时候从UWorkStealingQueue尾部弹出task。
需要说明的是,work-stealing机制也并不是一个万金油。比如,上面提到的头部/尾部弹出,明显会打乱任务执行顺序(当然,如果强要求顺序的话,可以考虑用优先队列构代替deque),所以这种机制更适合那种“可执行任务一把梭哈”的情况——对,我指的就是CGraph这种图执行框架——毕竟,其他情况我也不太了解啊,哈哈。
有些时候,work-stealing机制甚至可能成为“累赘”。举个例子,pool中一共有100个线程吧,那当thread0中queue无任务的时候,thread0会去遍历其他的99个thread——就为了盗取一个任务。这个遍历有阻塞耗时不说,也会影响到thread0去执行新来的local task——像极了天天帮同事排查bug,但是自己一大堆bug却来不及修复的纯序员本员。
我们之前提过local的内容亲和性是最高的,应该优先执行,对吧。针对这种情况,一种可行的解决办法是设定“盗取范围”(对应CGraph中的CGRAPH_MAX_TASK_STEAL_RANGE参数)。比如,thread0仅可以从相邻的3个线程(也就是thread1、thread2和thread3)中盗取任务,如果在这3个thread中都盗取不到,那就重新尝试看local的queue。其他线程亦是如此。也就是说,大家仅关系自己本地的task和自己若干个邻居的task,离得远的就不用问了。这种“事不关己高高挂起”(低情商说法)行为,在很多情况下却是好事,因为它还有一种高情商说法,就是“做好自己的本职工作(本分)”,嘿嘿。
随便放几句相关的代码哈,更多代码大家去github上面看哈。
/**
* 从其他线程窃取一个任务
* @param task
* @return
*/
bool stealTask(UTaskWrapperRef task) {
if (unlikely(pool_threads_->size() < CGRAPH_DEFAULT_THREAD_SIZE)) {
/**
* 线程池还未初始化完毕的时候,无法进行steal。
* 确保程序安全运行。
*/
return false;
}
/**
* 窃取的时候,仅从相邻的primary线程中窃取
* 待窃取相邻的数量,不能超过默认primary线程数
*/
int range = CGRAPH_MAX_TASK_STEAL_RANGE % CGRAPH_DEFAULT_THREAD_SIZE;
for (int i = 0; i < range; i++) {
/**
* 从线程中周围的thread中,窃取任务。
* 如果成功,则返回true,并且执行任务。
* 重新获取一下range,是考虑到动态扩容可能会影响
*/
int curIndex = (index_ + i + 1) % range;
if (nullptr != (*pool_threads_)[curIndex]
&& (((*pool_threads_)[curIndex]))->work_stealing_queue_.trySteal(task)) {
return true;
}
}
return false;
}
我实测的一个结果,在开16thread运行高并发(48路)大批量空跑task(就是所有的task都是return 0,这样可以一定程度体现出来pool的调度能力)调度的情况下,如果不设定steal范围,大概是194s的样子,而把steal范围设置为4之后,直接降低到了163s左右。不要问我怎么发现这个问题,火焰图会教你做人的。
| 本章小结 |
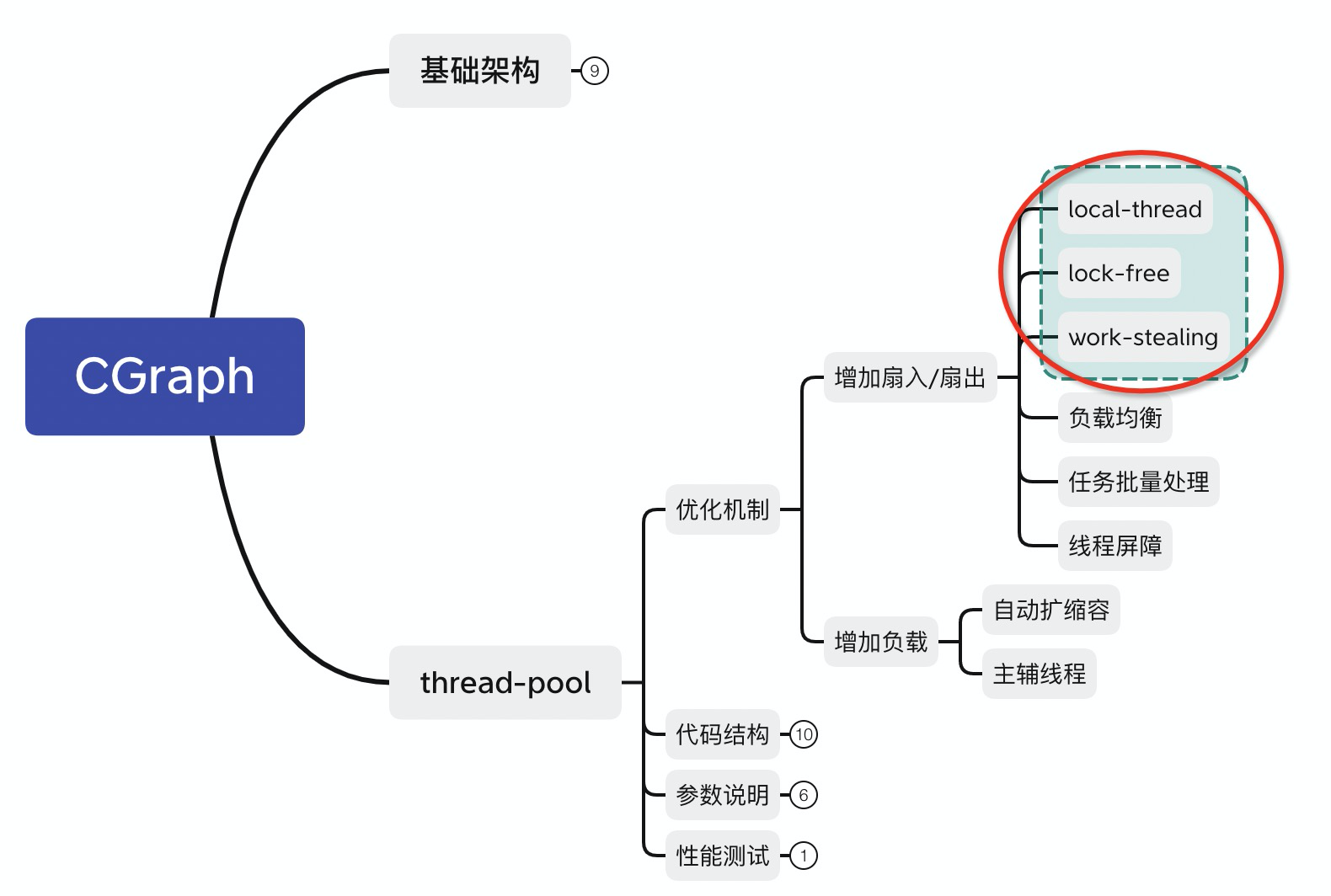
本章主要是介绍了一些线程池在设计过程中,有哪些优化点。总结一下就是下图中画红框的地方,主要的目的就是可以增加扇入扇出。今天分享的这几点偏硬核,都是我在自测过程中,的的确确可以增加调度性能的方案。我们也会在接下来的文章中,继续介绍CGraph中线程池的相关优化内容和思路。
如果你对这方面的内容也感兴趣,请加我微信(ChunelFeng)以便随时联系。有什么实用的功能,我们可以尝试去一起实现。有什么好的指教和意见,也欢迎随时提出来,以便我们改进和提高。
接下来一章,我们将会跟大家介绍一下其他的一些线程池优化机制,比如主辅线程、自动扩缩容等。欢迎大家继续关注。
[2021.08.01 by Chunel]
推荐阅读
- 纯序员给你介绍图化框架的简单实现——执行逻辑
- 纯序员给你介绍图化框架的简单实现——循环逻辑
- 纯序员给你介绍图化框架的简单实现——参数传递
- 纯序员给你介绍图化框架的简单实现——条件判断
- 纯序员给你介绍图化框架的简单实现——线程池优化(一)
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng
