大家好,我是不会写代码的纯序员——Chunel Feng。上一章中,我们主要聊到了thread-local机制、lock-free机制和work-stealing机制。今天,我们接着之前的话题,继续说说线程池优化的一些方法和实践,主要会涉及到:自动扩缩容机制、批量处理机制和负载均衡机制。
还是那句话,以下这些内容,仅局限于我个人的认知。如果有什么不对或者不合理的地方,很欢迎大家随时批评指正,也很希望大家可以提出自己意见、建议和看法。
首先,还是照例,先上源码链接:CGraph源码链接
其中,线程池的实现在/src/UtilsCtrl/ThreadPool/文件夹中
| 自动扩缩容机制 |
上一章,我们聊了一个问题:如果这个线程池中,忽然来了很多任务 (比如:吴亦凡出事了,大家都来微博疯狂围观点赞),这个时候怎么办?那过了一阵子,又忽然长时间没有任务可执行了 (比如:吴亦凡微博被官方屏蔽了)怎么办?还能怎么办,当然是心疼凡凡三秒钟了!!!
一个很通用的思路,就是自动扩缩容机制——在任务繁忙的时候,pool中多加入几个thread;而在清闲的时候,对thread进行自动回收。CGraph的实现逻辑中,包含了两种线程:PrimaryThread(主线程,简称PT)和SecondaryThread(辅助线程,简称ST),默认在程序运行的时候,启动CGRAPH_DEFAULT_THREAD_SIZE个PT去执行任务。在程序运行的过程中,PT的数量是恒定不变的,增/减的仅可能是ST——这一点,是参考Java中ThreadPool的机制。
如何判断pool是忙还是闲?可以使用running标记的方法 + TTL(time to live)计数的方法。除了PT和ST,pool中还开辟了一个MonitorThread(监控线程,简称MT)。MT每隔固定的时间,会去轮询监测所有的PT是否都在running状态。如果是,就认定当前pool处于忙碌状态,则添加一个ST帮忙分担任务执行。同样的,MT还会去监测每个ST的状态。如果连续TTL次监测到ST没有在执行任务,则认为pool处于空闲状态,则会销毁当前ST。
这样就做到了线程数量随着pool的忙碌和空闲,动态调整了。当然,ST的数量也不会无限增加的。当PT和ST的数量之和,达到CGRAPH_MAX_THREAD_SIZE值的时候,ST数量就只减不增了。
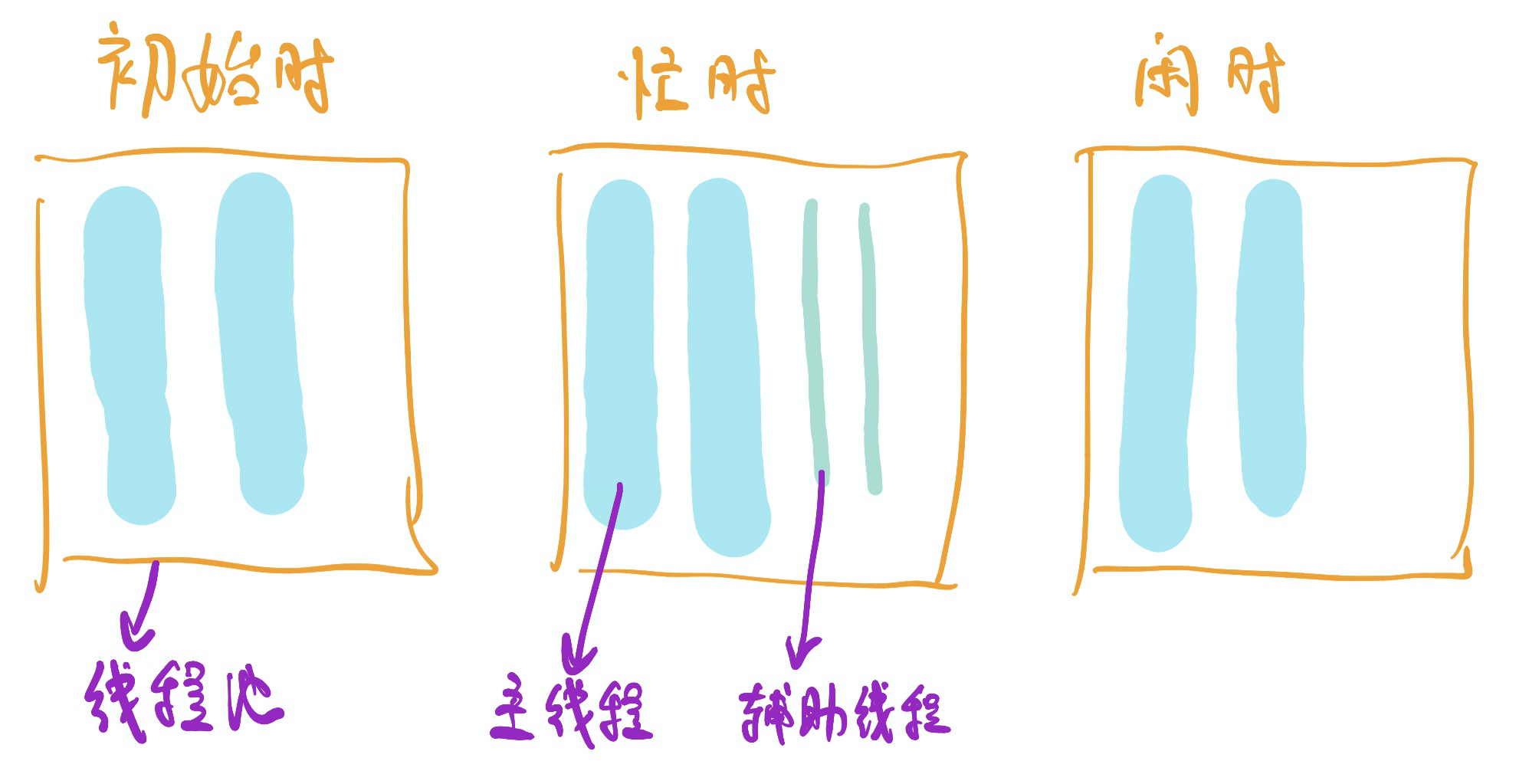
千万要避免的一个误区是:并不是线程开辟的越多,性能就越好。线程调度过程也是有损耗的。比如,在pool中开辟了1爽(约200+w)的线程,cpu就需要通过调度算法,来尽可能的保障每个线程都有时间片可以运行。那这其中线程来回切换的成本是很高的——很可能远高于任务执行的成本。讲通俗一点就是:一个和尚挑水喝,两个和尚抬水喝,三个和尚没水喝。
在其他文章中,也看到过一些意见,比如:
- 计算密集型任务,开辟
n或n+1个(其中,n=cpu核数)线程数 - IO密集型任务,开辟
2n+1个线程
也看到有童鞋列出来一个公式,根据任务的耗时等参数,来预估合理的线程数量。类似:
- 最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
我想说的是,这些有道理,也值得参考。但适合的配置参数,最好还是带入实际任务中测试和检验。实测,是检验性能的唯一标准。Talk is cheap, show me the test.
CGraph的线程池源码中,给PT和ST做出一些差别对待。PT中有自己的任务队列,执行task的顺序依次是:local -> pool -> steal,即:先执行自己任务队列中的task;如果自身的queue为空,则执行pool中的task;如果仍没有任务,就从相邻的n个PT中去steal(具体逻辑请看上一章内容)。而ST没有属于自己任务队列,仅可以执行pool中的queue的任务,对应代码也就是popPoolTask(task)这部分。
/* 主线程执行task的逻辑 */
void runTask() {
UTaskWrapper task;
if (popTask(task) || popPoolTask(task) || stealTask(task)) {
is_running_ = true;
task();
is_running_ = false;
} else {
std::this_thread::yield();
}
}
这样做的原因,一方面是可以从代码层面,突出主辅的层次感。更重要的一方面是保证了ST释放的时候不容易出错或丢失任务,并且不让work-stealing的过程变得更复杂。
| 批量处理机制 |
上一章,提到线程池优化的一个基本出发点就是 增加扇入扇出。为了在这一点上做到更优,CGraph在从queue中获取task的时候,提供了批量获取tasks的功能。在开启CGRAPH_BATCH_TASK_ENABLE参数之后,PT和ST在从queue中获取/盗取task的时候,就不再是one by one的获取,而是batch by batch的获取。这样做的最大好处,是可以减少线程获取task时候,争抢锁的次数,从而提升性能。
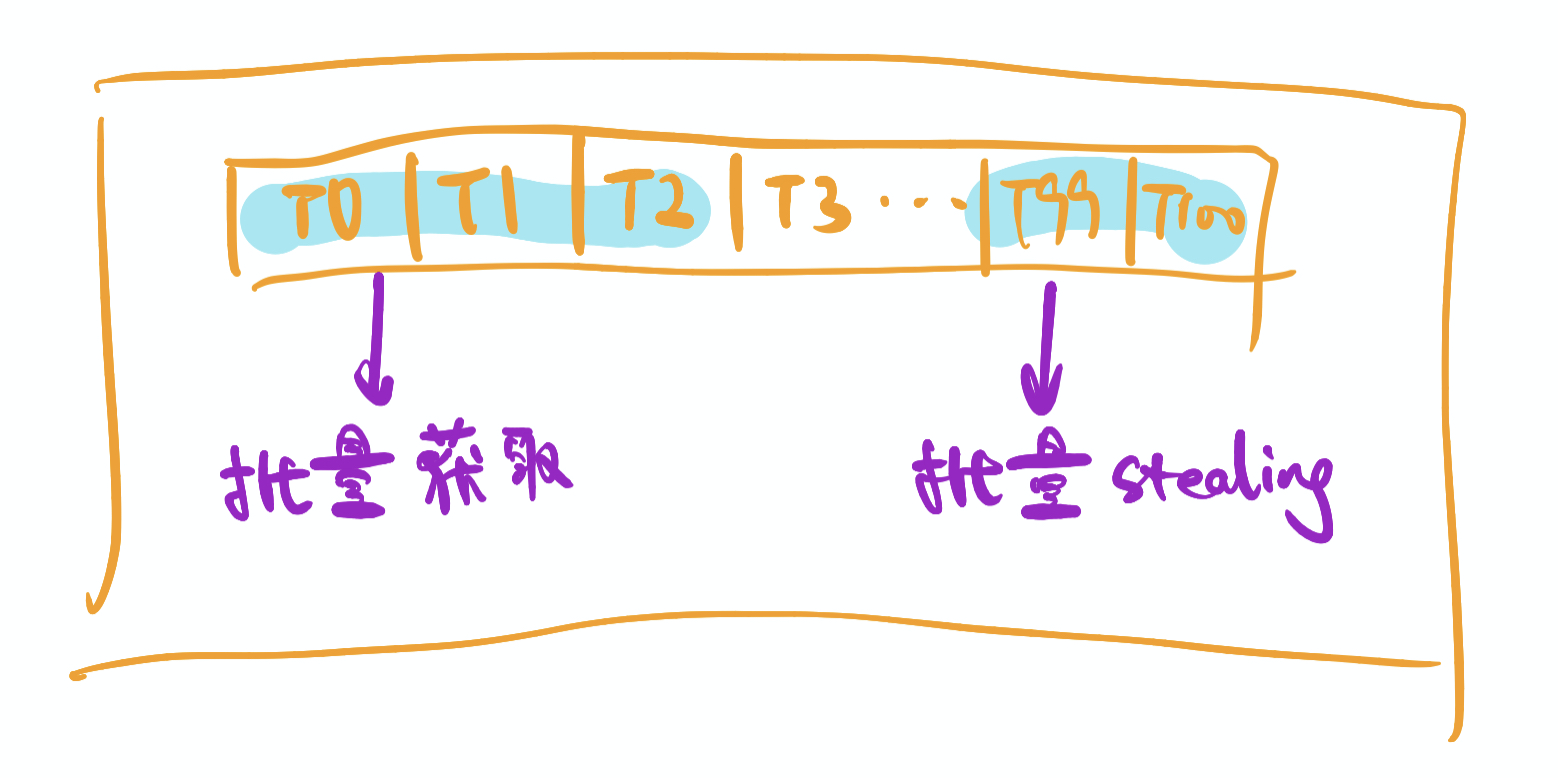
这种机制也可能会打乱queue中任务的执行顺序,单独使用的时候需要慎重考虑。但是,针对图化框架这种情况,并没有这种担忧。放入线程池中执行的任务,均是“互不依赖”的,也就是“无序执行”的——因为有依赖的节点,会等待被依赖节点执行完毕后,才被放入pool中。
即便是这样,也不能无脑使用。设想一种情况,pool中有4个PT,任务队列中共有100个sleep 1s;的任务。一个PT过来一批拉走了这100个任务,然后就默默的运行了100s,而其他所有的线程都在旁边鼓掌么?这样做的好处,是原先需要有100次的抢锁过程被缩减到了1次。但是坏处吗,原先约25s就可以执行完的任务,硬生生的被执行100s。
/**
* 从头部开始批量获取可执行任务信息
* @param taskArr
* @return
*/
bool tryMultiPop(UTaskWrapperArr& taskArr) {
bool result = false;
if (mutex_.try_lock()) {
int i = CGRAPH_MAX_TASK_BATCH_SIZE;
while (!queue_.empty() && i--) {
taskArr.emplace_back(std::move(queue_.front()));
queue_.pop_front();
result = true;
}
mutex_.unlock();
}
return result;
}
为了对这样的情况做出权衡,CGraph中提供了CGRAPH_MAX_TASK_BATCH_SIZE参数。在开启批量拉取功能后,每个线程每次拉取task的数量不能超过该数值,这样在一定程度上在兼顾了增加扇出和减少抢锁次数这两个方面,又尽可能的缓解了刚才提到的那种极端情况。
需要说明的是,真实的多线程情况远比我们刚才讨论的复杂。现代计算机的调度理论何其深奥和精密,我想即便是Bill Gates、Linus Torvalds,甚至是Kris Wu,也无法穷尽其中奥秘。而多线程自身又有很多的不确定性。所以,具体采用哪种执行策略,还是尽可能的去模拟真实环境进行实测和压测,这样得出来的结果才最有说服力——这话,我好像说了三遍了。
| 负载均衡机制 |
负载均衡问题,是调度方面性能优化的一个永恒的话题。针对不同任务和不同情况,有不同的对应策略。之所以放在最后一点说,主要是因为个人水平和见识有限,CGraph的线程池中,在这方面并没有做太多的优化。只是将一部分任务均匀的写入PT的queue中,另一部分统一放到pool的queue中。但即便是这样,也已经比传统的线程池做法,在性能上优化了不少(关于性能测试,我会在后面的文章中介绍)。
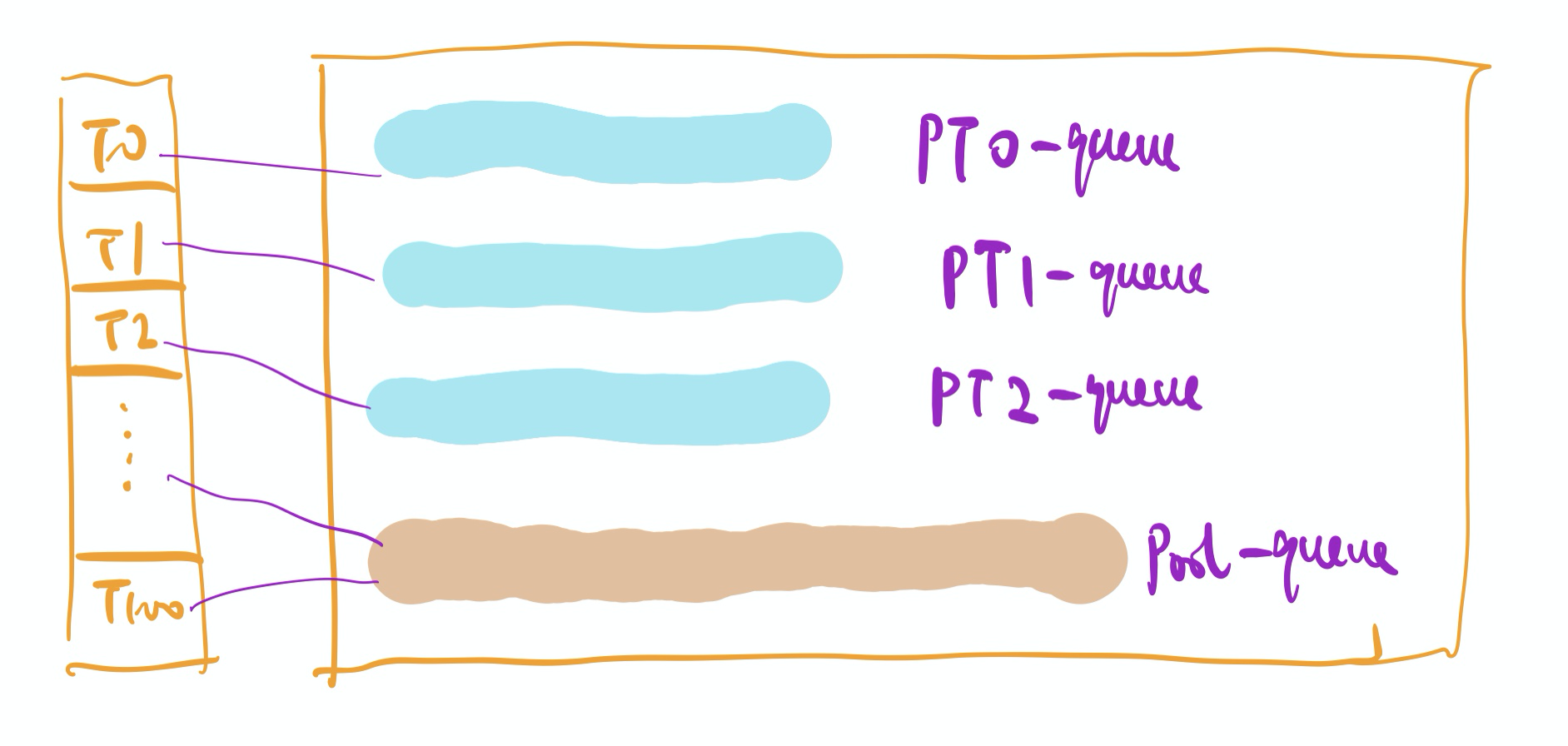
如果是要针对这方面做一些优化的话,我提两点我的看法吧:
- 尽可能的保证当前PT中产生的task,放入本PT的queue中执行,也算是迎合thread-local的概念。
- 尽可能保证每个PT的queue中,任务耗时总和基本一致。不要频繁出现work-stealing的情况。
| 本章小结 |
本章内容,主要跟大家介绍了线程池的一些优化思路,包括:自动扩缩容、批量处理和负载均衡。梳理了它们在使用过程中,能够解决的一些痛点和可能遇到的一些坑。
面对不同数量、不同耗时、不同功能(IO密集、计算密集)、不同顺序的任务的各种实际情况,很难说有可以一招打遍天下的诀窍。很多情况下,还是需要靠实测、压测和专业分析工具,来看出性能瓶颈点。为此,CGraph也在源码中开放出来了一些配置参数供大家选择尝试。
推荐一个我平时用的性能监测工具:Profile,它可以集成在CLion中一键执行,并生成火焰图。看下面这张图,基本上一眼就可以看出来,任务执行的耗时基本上卡在runTask()函数中。至于为什么会这样?能否优化?如何优化?这些问题就要自己一点点根据代码分析了——测试,永远也不会告诉你答案了。

有一说一,最近比较流行的协程的概念,应该也比较适合做这种调度的场景,而且人为可控性更强。我们上面提到的一些优化方法,也参考Java中的一些现有实现逻辑。如果有懂Go大佬可以指教一下,我想那就更好了。

[2021.08.07 by Chunel]
推荐阅读
- 纯序员给你介绍图化框架的简单实现——执行逻辑
- 纯序员给你介绍图化框架的简单实现——循环逻辑
- 纯序员给你介绍图化框架的简单实现——参数传递
- 纯序员给你介绍图化框架的简单实现——条件判断
- 纯序员给你介绍图化框架的简单实现——线程池优化(一)
- 纯序员给你介绍图化框架的简单实现——线程池优化(二)
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng
