大家好,我是不会写代码的纯序员——Chunel Feng。各位绅士们,很高兴又在这里跟大家相见了。
在之前的几篇文章里,我们先是讨论了原生C++对多线程编程支持的匮乏,然后又分别从线程调度层面和工程实现层面,给介绍了一些线程池优化的实用思路,主要包括:local-thread机制、lock-free机制、work-stealing机制、自动扩缩容机制、批量处理机制、负载均衡机制、避免busy-waiting、分支预测优化和减少无用copy。真心希望以上内容,会对大家有所帮助。
本章内容,是这个线程池系列的最后一章。我们会先介绍一下CGraph中threadpool的使用demo,并提供出来实测的一些数据,来佐证我们之前的各种努力,的确达到了优化的效果。同时也会畅想一下今后可能的优化方向和扩展点(思路已有,就差一个会写代码的程序员了,嘿嘿)。
首先,还是照例,先上源码链接:CGraph源码链接
其中,线程池的实现在/src/UtilsCtrl/ThreadPool/文件夹中
| 使用Demo |
首先,来看一个简单的使用demo吧。
我们在线程池优化第一章中,立flag的时候说过,threadpool要可以支持任意入参和返回值的任务执行,并且简单好上手。下面这段代码,分别定义了4种函数:普通函数,静态函数,类成员函数,类成员静态函数。
int add(int i, int j) {
return i + j;
}
static float minusBy5(float i) {
return i - 5.0f;
}
class myFunction {
public:
std::string pow2(std::string& str) const {
int result = 1;
int pow = power_;
while (pow--) {
result *= (int)atoi(str.c_str());
}
return "multiply result is : " + std::to_string(result);
}
static int divide(int i, int j) {
if (0 == j) {
return 0;
}
return i / j;
}
int power_ = 2;
};
下面一段代码,主要展示了如何通过CGraph中的threadpool来执行以上几种函数,并且说明了如何做阻塞等待。
void tutorial_threadpool() {
UThreadPoolPtr tp = UThreadPoolSingleton::get(); // 通过单例方式获取
int i = 6, j = 3;
std::string str = "5";
myFunction mf;
/**
* 可以通过lambda表达式传递函数
* 也可以传入任意多个参数
* 方法返回值也可以是任意类型
*/
auto r1 = tp->commit([i, j] { return add(i, j); });
auto r2 = tp->commit(std::bind(minusBy5, 8.5f));
auto r3 = tp->commit(std::bind(&myFunction::pow2, mf, str));
std::future<int> r4 = tp->commit(std::bind(&myFunction::divide, i, j)); // commit()返回值,实际上是一个std::future<T>类型
/**
* 返回值可以是int、string等各种类型
* 调用get()方法,表示阻塞等待改函数执行完毕
* 不调用get()方法,表示不阻塞等待
*/
std::cout << r1.get() << std::endl;
// std::cout << r2.get() << std::endl; // 不阻塞等待该函数执行完毕
std::cout << r3.get() << std::endl;
std::cout << r4.get() << std::endl;
}
代码行数不多哈,整体也比较easy,也没啥好说的。从我实际做(B)开(U)发(G)的经验来说,支持以上这几种函数,就可以完成基本所有方法的调度了。
需要强调的一点就是,针对threadpool这一块,我进行过亿次以上的任务写入测试,功能也都是稳定可靠的。

| 性能对比 |
一波骚操作之后,我们终于还是要出一下性能测试报告的。在这里捏,我最后说一遍,多线程实际执行的情况复杂,实际性能数据需要带入实际环境大量实测。
我们接下来的测试数据,主要就是跟最常见的one input, one output的threadpool写法进行对比,具体链接我就不上了,大家github或者*乎上直接搜索一下就好。
测试的方法呢,主要就是高并发大批量空跑return 0;的任务,从而考察线程池的调度能力。还有要说明的,就是实验结果并非单纯测试线程池本身,而是通过在CGraph框架中,并发跑 并发数 个任务,然后等待批量任务执行完毕后再跑下一轮,一共跑 执行次数 轮。
由于常规线程池并不包含自动扩缩容机制,在测试过程中,也是保证CGraph中的线程数量max和default值也设置为相同的。
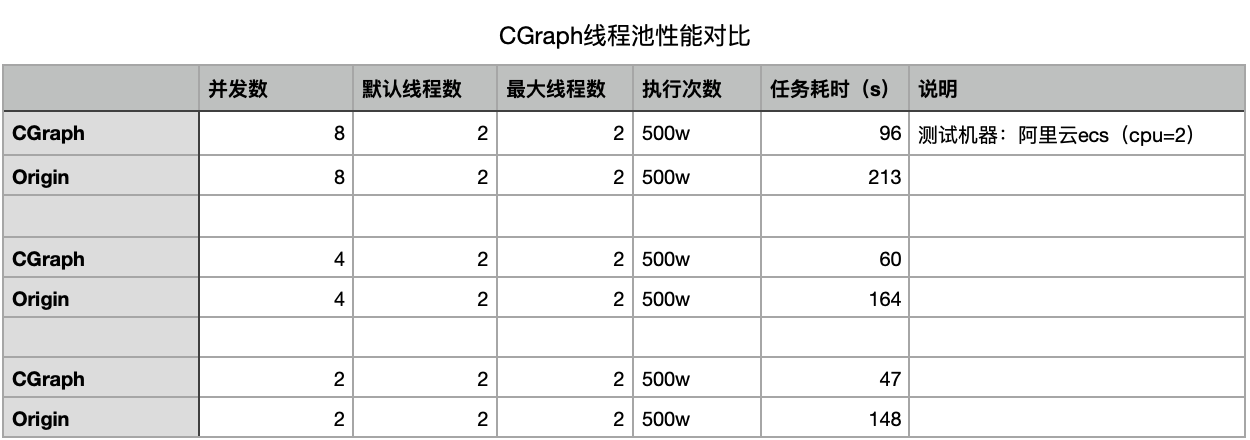
测试的结果,更多是在比较CGraph在使用传统线程池和优化后的线程池时,空跑调度任务的性能差距。旨在说明以上提出的优化方案切实有效。

在这里,也给大家推荐其他几个C++常用的并行库:openmp,tbb等,还有很多国内互联网巨头公司提供出来的相关开源组件,大家也可以去尝试看看。
#include <iostream>
#include <omp.h>
#include <tbb/tbb.h>
void myPrint(int x) {
std::cout << x << std::endl;
}
void openmp_version() {
/* openmp版本,并发打印0~99 */
#pragma omp parallel for num_threads(4)
for(int i = 0; i < 100; i++) {
myPrint(i);
}
}
void tbb_version()
{
/* tbb版本,并发打印0~99 */
tbb::parallel_for(0, 100, 1, myPrint);
}
void cgraph_version() {
/* CGraph版本,并发打印0~99 */
UThreadPoolPtr tp = UThreadPoolSingleton::get();
for (int i = 0; i < 100; i++) {
tp->commit([i] { myPrint(i); });
}
}
int main() {
openmp_version();
tbb_version();
cgraph_version();
return 0;
}
并发编程是一个很常见的话题。通用的方法很多,也各有优劣,建议大家在选择和使用的时候多思考,多比较。在成长的过程中,不是很建议陷入那种“这个项目之前就是用的xx方法,所以我也就用了”的怪圈。当然,如果在现实工作中,考虑到功能稳定性、一致性、快速迭代和可维护性的话,那就又另当别论了。
| TODO |
以上说了这么多,都是在说好的地方:做了哪些优化,加了哪些功能。在快要结束的时候,也要总结一下CGraph中的threadpool中还有哪些功能的缺失和不足。
任务优先级
我们之前提过,local-thread机制和批量执行机制,会使得threadpool中的任务执行顺序,和实际写入顺序变的不一致。关于这一点,我们提供了CGRAPH_FAIR_LOCK_ENABLE参数(默认为false),如果设置为true则任务执行顺序和任务写入顺序保持一致。
不过,还有一个很实际的问题:有些情况下,不同任务的优先级就是不同的,优先级高的任务,理应优先被执行。这个时候,线程池中任务的存储方式就应该从queue改为priority_queue了,当然肯定还会牵扯到一些其他的改动,有兴趣的话可以尝试去实现一下。
拒绝策略
任务写入threadpool中,是瞬间的动作,但是有些任务执行起来就需要很长的时间,比如:sleep(100);。当线程池中源源不断的写入大量任务,却无法及时消费的时候,是可能引发各种意想不到的问题,甚至程序崩溃的。所以,一个优秀的线程池中还应该有拒绝策略,比如:内部未执行任务超过1爽(约208w)之后,就外部任务就无法继续写入了。
拒绝策略又可以区分为严格的拒绝策略和宽松的拒绝策略。严格,主要体现在写入任务的瞬间,如果pool中的任务数量正好是1爽的时候,就拒绝;宽松,就可以是pool中的任务数量超过1爽之后的若干秒后,pool开始拒绝外部写入,直到其中任务被消费到小于1爽之后的若干秒后,又恢复正常。
严格和宽松,没有绝对的优劣之分,只有各自适合和不适合的场景。如果有时间,可以尝试去实现一下。
cas机制
我们之前也提过,cas属于无锁编程技术的一种。再次申明,并不是通过无锁编程的实现方式,性能就一定高于有锁编程。不过,这也是一个很值得尝试的优化点。等排期哦哦哦,哈哈。

| 本章小结 |
本章节是我们关于线程池优化的最后一篇了,我把个人对线程池的理解,基本上都写在了这几篇文章里了。并发编程本身博大精深,而个人水平和时间都有限,很难讲解的非常深入。在写文章的过程中,也竭尽全力对自己的每一处描述做了验证,力求正确无误,却仍可能存在一些认知的盲区和错误的描述,希望大家不吝指教。
虽然还存在诸多的不完美,但还是非常开心能从一而终的把代码和文章写完,并在github上和这里跟大家分享。C++线程池我之前在工作中用到过,但是并没有做过什么优化和改进。通过这一个月自己闲暇时间的摸索和学习吧,我个人是有了一些自己的积累和进步,也希望可以通过分享,对大家有一丝的帮助和启发。
在这个过程中,也有幸得到了阿里云、搜狗和旷视等一流公司资深大佬的一些指导,在这里再次深表感谢。如果说自己的既有行动是“99%的努力”的话,那高人的点拨更像是“1%的灵感”,让我受益匪浅,足以提升一个层次。同时,也很感谢我的女神,在这期间一直不回我微信,也约不出来,好让我有了足够多的时间来撸代码和写文章。
最近,也通过写博客和公众号,认识了不少新朋友。很高兴认识大家,很感谢大家的关注和一键三连。同样感谢几位朋友的打赏,就像一杯午后的咖啡,不贵,但很暖心。
接下来,在日常的工作之余,我会把业余的时间投入到Caiss的图化框架移植中去。希望通过CGraph框架,给大家带来一些更好的向量相似搜索的体验。
最后的最后,下面是我的微信二维码,欢迎大家加我微信,随时交流聊天,多多指教。添加的时候,请加上简单个人备注信息,不然的话,一律标注为“大姨妈介绍的相亲对象”,哈哈。

[2021.09.04 by Chunel]
推荐阅读
- 纯序员给你介绍图化框架的简单实现——执行逻辑
- 纯序员给你介绍图化框架的简单实现——循环逻辑
- 纯序员给你介绍图化框架的简单实现——参数传递
- 纯序员给你介绍图化框架的简单实现——条件判断
- 纯序员给你介绍图化框架的简单实现——线程池优化(一)
- 纯序员给你介绍图化框架的简单实现——线程池优化(二)
- 纯序员给你介绍图化框架的简单实现——线程池优化(三)
- 纯序员给你介绍图化框架的简单实现——线程池优化(四)
个人信息
微信: ChunelFeng
邮箱: chunel@foxmail.com
个人网站:www.chunel.cn
github地址: https://github.com/ChunelFeng
